
OmniSQL 是开源的文本到 SQL 模型,将自然语言问题高效转换为 SQL 查询语句。通过创新的数据合成框架生成了全球首个百万量级的文本到 SQL 数据集 SynSQL-2.5M,包含 250 万条高质量样本,覆盖 16,000 余个跨领域数据库,样本涵盖多种复杂度层级和语言风格。OmniSQL 提供 7B、14B 和 32B 三种参数规模,不同规模适配不同算力需求,从个人开发到企业级应用,都能找到合适版本,微调过程中融合了 Spider 和 BIRD 的高质量标注数据。

OmniSQL的主要功能
- 文本到SQL转换:OmniSQL能理解用户以自然语言形式提出的问题,转换为对应的SQL查询语句。
- 支持多种数据库和复杂查询:OmniSQL支持多种数据库类型,能处理从简单单表查询到复杂的多表连接、子查询、函数调用以及公共表表达式(CTE)等各种复杂度层级的SQL查询。
- 提供思维链解决方案:除了生成SQL查询语句外,OmniSQL会为每个样本提供一个思维链解决方案。这个思维链展示了从理解自然语言问题到生成SQL查询的逻辑推理过程,有助于用户更好地理解模型的决策路径,同时也便于开发者对模型进行调试和优化。
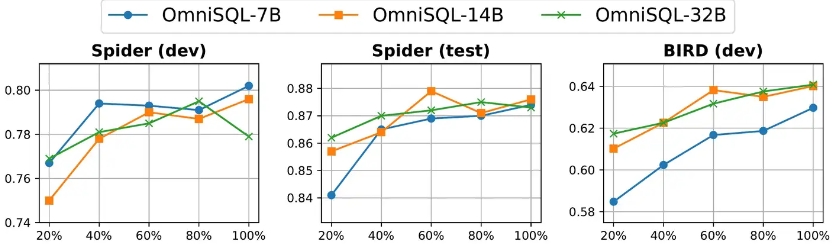
- 多模型版本选择:OmniSQL提供了三种不同大小的模型版本,分别是7B、14B和32B。用户可以根据自己的实际需求和计算资源情况选择合适的模型版本。不同规模的模型在性能和资源消耗之间进行了平衡,较小的模型运行速度更快、资源占用更少,较大的模型则可能在某些复杂查询场景下表现更好。
OmniSQL的技术原理
- 数据库自动生成:OmniSQL分析网络表格,推断业务场景,借助大语言模型自动构建含多表关系、主外键约束的数据库结构。采用增强策略,增加列数、优化结构,让生成的数据库更贴合实际应用。
- 复杂度感知的SQL查询生成:定义四个复杂度等级,结合SQLite函数库,如聚合函数(SUM、AVG等)、窗口函数(ROW_NUMBER、RANK等),生成各类SQL查询。能依用户问题智能选择复杂度等级,给出合适查询语句。
- 风格化问题反向翻译:采用SQL-to-Question策略,将SQL查询反向译为9种语言风格的自然语言问题,经语义分析确保翻译前后语义一致,提升自然语言与SQL转换效率和准确性,适应不同用户语言习惯。
- CoT解决方案合成:通过逐步推理生成器,为样本添加中间推导步骤。训练时,模型学习问题到SQL的转换,也学习每步推理逻辑,提高推理准确性与可靠性,向用户展示透明推理过程,增强信任。
- 大规模数据合成与训练:OmniSQL基于其数据合成框架生成了大规模的高质量训练数据集SynSQL-2.5M。数据集包含超过250万条样本,覆盖了16,000余个跨领域的数据库。通过在如此大规模且多样化的数据集上进行训练,OmniSQL能学习到不同领域、不同风格的自然语言表达与SQL查询之间的映射关系,具备更强的泛化能力和适应性。
OmniSQL的项目地址
- Github仓库:https://github.com/RUCKBReasoning/OmniSQL
- arXiv技术论文:https://arxiv.org/pdf/2503.02240
OmniSQL的应用场景
- 企业数据分析:OmniSQL 通过自然语言查询功能,让非技术人员能轻松地从数据库中获取所需信息。
- 教育领域:在 SQL 教学中,OmniSQL 的链式思考(CoT)解决方案能够帮助初学者更好地理解从自然语言问题到 SQL 查询的转换过程。教师可以用 OmniSQL 生成查询示例,让学生通过实际操作来掌握 SQL 的概念和技巧。
- 跨领域适配:OmniSQL 基于其数据合成框架,能快速生成特定领域的数据集。在医疗领域,可以生成 EHRSQL 数据集,助力医疗研究;在科研领域,可以生成 ScienceBenchmark 数据集,辅助科研数据分析。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...